SQL Server全文索引的硬伤
发布时间:2011-08-30 13:54 来源:未知
想象这样一个场景:在DataBase_name.dbo.Table_name中有一个名为Title(标题)和Contents(内容)的字段,现在需要查询在Title或者Contents中包括“qq”字符的所有记录。
面对这样的一个场景,我们通常都会写这样一个脚本:SELECT * FROM DataBase_name.dbo.Table_name WHERE Title LIKE '%qq%' OR Contents LIKE '%qq%'; 没错,这也是我第一个想到的方法。
但是我们需要思考的是:随着时间的推移,数据会越来越大,那个时候我们该如何提高我们的性能 客户随时都有可能要求加入对Remark(备注)字段的查询,难道我们就应该不厌其烦地修改程序代码
面对上面的质问,我们需要提醒你的是:①对于这样的查询条件,即使Title和Contents上都有索引,我们也无法使用到索引,因为在 '%qq%'的“qq”前面使用了通配符,所以无法使用到索引;假如查询的条件是'qq%',那倒是可以利用上索引。②在许多数据库性能调优的文章上都说OR这个谓词可以使用SELECT UNION ALL SELECT这样的方式来提高性能,但是需要提醒大家的是:假如在一条记录中字段Title和Contents都同时存在“中国”字符的话,那么返回的结果就会出现两条相同的记录,假如你希望是唯一的记录,那么这个时候你就要注意了。③其实有些时候,对于and的操作符,我们可以考虑使用:SQL Server 索引中include的魅力(具有包含性列的索引)
现在回到我们上面提出的疑问上,大概这个时候大家都应该想到了数据库的全文索引了。全文索引是一种特殊类型的基于标记的功能性索引,由 Microsoft SQL Server 全文引擎 (MSFTESQL) 服务创建和维护。创建全文索引的过程与创建其他类型的索引的过程差别很大。MSFTESQL 不是基于某一特定行中存储的值来构造 B 树结构,而是基于要索引的文本中的各个标记来创建倒排、堆积且压缩的索引结构。(摘自MSDN)
讲了那么久,硬伤在哪里呢 可能大家都怀疑我是不是标题党了,呵呵,马上就讲到,那就是这个全文索引能解决我们一开始提到的场景吗 回答是否定。为什么呢 因为SQL Server对字符串“tqq.tencent.com”进行分词和倒排索引后,我们是无法通过查询条件‘“*qq*”’来返回上面那条字符串的记录的,这样的查询条件只能查询到类似“qqt.tencent.com”、“www.qq.com”这样的字符串。SQL Server的分词应该是正向最大值的分词方法,它没有把字符串进行反方向再进行一次分词和索引,所以只能查询到词或短语的前缀符合的记录。这一点有可能会被大家所忽略掉。
就针对上面的说法,我们来进行测试一下:
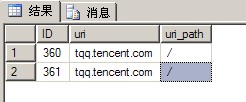
--已经对表Test_FullText_Index的uri,uri_path建立了全文索引. --下面的查询是为了说明CONTAINS与LIKE的区别. SELECT ID,uri,uri_path FROM Test_FullText_Index where uri LIKE '%qq%' AND ID NOT IN(SELECT ID FROM Test_FullText_Index WHERE CONTAINS(uri,'"qq*"')) --下图为执行结果
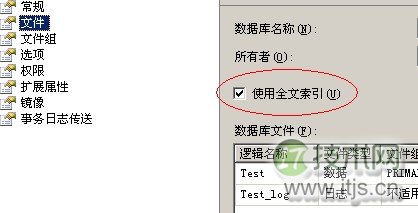
如何大家有什么好的解决方案可以解决这样的Like查询的话,可以拿出来大家探讨一下。 主题的内容讲完了,下面附带讲一些创建全文索引的步骤和注意事项,懂的童鞋(同学)可以跳过。 设置全文索引的步骤 1:对着数据库点击右键-选择属性-选择文件,选中“使用全文索引” 2:对着表点击右键-全文索引-定义全文索引 3:点击下一步,假如这个表中没有唯一性索引就会出现下图所示 4:选择表列,选择断字符语言。 5:点击下一步,这里的选项要注意,假如不想再表、视图更改的时候更新全文索引,那就选择不跟踪更改;这样就可以选择是否在创建索引时启动完全填充了。 6:点击下一步创建索引要保存的目录,全文索引的索引文件是以文件的形式保存到硬盘上的。 7:之后就可以设置自动填充、手动跟踪更改,还有设置计划了。 全文索引需要注意: CONTAINS的几种用法 CONTAINS 谓词可以搜索: 原文链接:http://www.cnblogs.com/gaizai/archive/2010/05/13/1733857.html