一致性哈希算法原理设计
发布时间:2014-11-27 00:00 来源:知致智之
一.前言
一致性哈希(Consistent Hashing),最早由MIT的Karger于1997年提出,主要用于解决易变的分布式Web系统中,由于宕机和扩容导致的服务震荡。现在这个算法思路被大量应用,并且在实践中得到了很大的发展。
二.算法设计
1.问题来源
一个由6台服务器组成的服务,每台Server负责存储1/6的数据,当Server1出现宕机之后,服务重新恢复可用时的场景。
如下表格可以很清楚的看到,当Server1宕机时,Hash1的服务完全不可用了,所以需要ReHash由剩余5台机器提供所有的数据服务,但由于每台机器负责的数据段大小不相同,那么需要在不同的服务器之间大量迁移数据,并且数据迁移完成之前服务会不可用。

2.经典一致性哈希算法
针对ReHash的弊端,Karger提出了一种算法,算法的核心是”虚拟节点”。
将所有的数据映射成一组大于服务器数量的虚拟节点,虚拟节点再映射到真实的服务器。所以当服务器宕机时,由于虚拟节点的数量固定不变,所有不需要ReHash,而只需要将服务不可用的虚拟节点重新迁移,这样只需要迁移宕机节点的数据。
经典的算法中,宕机服务器的下一个真实节点将提供服务。

三.算法改进
1.经典一致性哈希算法的问题
经典的算法只是解决了ReHash算法的缺陷,当本身并不完美。主要存在以下几个问题:
(1)Server1宕机会导致Server2的服务承受一倍的数据服务,且假如Server1就此退役,那么整个系统的负载完全不均衡了。
(2)假如所有的Server都能承受一倍的数据读写,那么假如在正常情况下所有的数据写两份到不同的服务器,主备或者负载均衡,宕机时直接读备份节点的数据,根本不需要出现经典算法中的数据迁移。
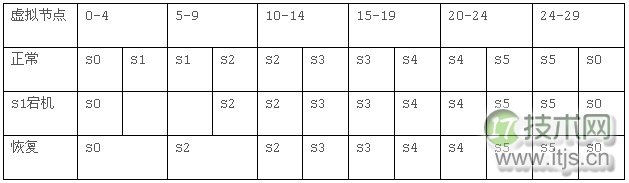
2.Dynamo改进实践
Amazon的大数据存储平台”Dynamo”使用了一致性哈希,但它并没有使用经典算法,而是使用了故障节点ReHash的思路。
系统将所有的虚拟节点和真实服务器的对应关系保存到一个配置系统,当某些虚拟节点的服务不可用时,重新配置这些虚拟节点的服务到其他真实服务器,这样既不用大量迁移数据,也保证了所有服务器的负载相对均衡。
| 虚拟节点 | 0-4/5 | 10-14/6 | 15-19/7 | 20-24/8 | 24-29/9 |
| 恢复 | Server0 | Server2 | Server3 | Server4 | Server5 |
四.算法扩展
一致性哈希算法本身是用于解决服务器宕机与扩容的问题,但”虚拟节点”的算法思想有所发展,一些分布式的系统用于实现系统的负载均衡和最优访问策略。
在真实的系统情况下,相同部署的两套系统可能不能提供相同的服务,主要原因:
(1)硬件个体差异导致服务器性能不同。
(2)机房交换机和网络带宽导致IDC服务器之间的网络通信效率不同。
(3)用户使用不同的网络运营商导致电信IDC和联通IDC提供的服务性能不同。
(4)服务器所在网络或机房遭遇攻击。
所以完全相同的两套系统可能也需要提供差异化的服务,通过使用虚拟节点可以灵活的动态调整,达到系统服务的最优化。
对于由2个节点,每个节点3台服务器组成的分布式系统,S0-1为分布式系统1的Server0,系统配置管理员可以根据系统真实的服务效率动态的调整虚拟节点与真实服务器的映射关系,也可以由客户系统自身根据响应率或响应时间等情况调整自身的访问策略。
| 虚拟节点 | 0-2 | 3-4 | 5-7 | 8-9 | 10-12 | 13-14 |
| 服务器 | S0-1 | S0-2 | S1-1 | S1-2 | S2-1 | S2-2 |




