

Java 8 对自带的排序算法进行了很好的优化。对于整形和其他的基本类型, Arrays.sort() 综合利用了双枢轴快速排序、归并排序和启发式插入排序。这个算法是很强大的,可以在很多情况下通用。针对大规模的数组还支持更多变种。我拿自己仓促写的排序算法跟Java自带的算法进行了对比,看看能不能一较高下。这些实验包含了对特殊情况的处理。
首先,我编写了一个经典的快速排序算法。这个算法通过计算样本的平均值来估计整个数组的中心点,然后用作初始枢轴。
我借鉴了一些Java的思路来适当改进我的快速排序,修改后的算法在对小数组进行排序的时候直接调用了插入排序。在这种情况下,我的排序算法和Java的排序算法可以达到相同的运行时间量级。Wild & al 指出,假如排序数组有很多的重复数据,标准的快速排序会比双枢轴的快速排序要快。我没有尝试任何字节或汇编级别的分析和优化。在大部分的问题中,我的版本的优化程序都远远不能跟Java系统程序相提并论。
我一直都想测试脑海里的一个简单的排序算法,我称之为Bleedsort。这是一个分布式算法,它通过样本抽样方法对要排序的数组进行分布估计,根据估计结果把数据分配到相应的一个临时的数组里(如图 1 所示),并重写这个初始的数组。这是一个预处理过程,然后再应用其他的排序算法分别进行排序。在我的测试中,我使用了我编写的快速排序版本。假如使用合并排序应该会有更好的结果,因为合并排序被广泛应用在高度结构化的数组中。为了计算简单,我只测试了分布均匀的数据。
Bleedsort在遇到相同的数据的时候都会放到右边,所以此算法在排序相对一致(译者注:会有很多重复数据)的数组的时候表现很差。所以我需要对排序的数组进行样本估计,当重复数很多的情况下应避免使用Bleedsort算法。
我很清楚,Bleedsort算法在内存空间使用方面没办法跟归并排序(快速排序)相提并论,临时数组也比原来的数组要大四倍左右。同时其他的一些分布排序算法,比如Flashsort,在这方面也表现得要好很多。
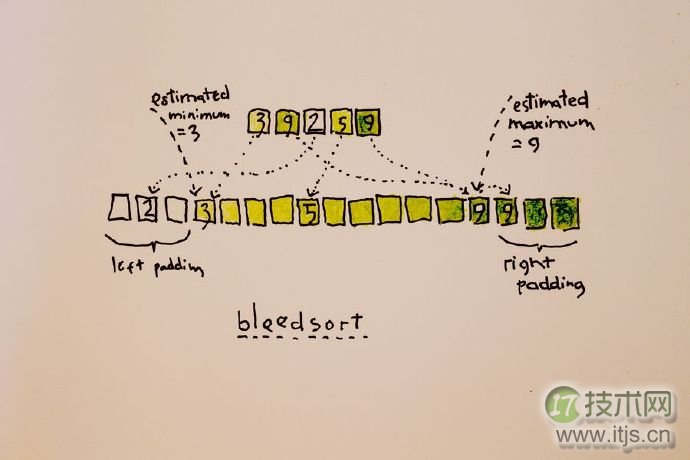
图1 Bleedsort举例说明
我运用JMH来作为测试基准。为了简单起见,我就用整形数组进行测试。在1000.000 到10.000.0000 数量级的均匀分布的数组中,我的算法表现的最好。尽管我写的快速排序算法在一定程度上比不过Java自带的算法,但是我的预处理过程很好的弥补了这些不足(调用了我的快速排序的Bleedsort 87ms vs Java 自带算法105ms; 938ms vs 1.144s)
Benchmark Mode Cnt Score Error Units Corrected MyBenchmark._1e6U sample 8512 0.024 ± 0.001 s/op MyBenchmark._1e7U sample 985 0.236 ± 0.001 s/op 我生成了下面这些正确的基准数组 MyBench.int1e6UQuickSort sample 1641 0.131 ± 0.001 s/op 0.107 ± 0.002 MyBench.int1e6UBleedSort sample 2410 0.087 ± 0.001 s/op 0.063 ± 0.002 MyBench.int1e6UJavaSort sample 1978 0.105 ± 0.001 s/op 0.081 ± 0.002 MyBench.int1e7UQuickSort sample 200 1.483 ± 0.014 s/op 1.459 ± 0.015 MyBench.int1e7UBleedSort sample 373 0.938 ± 0.009 s/op 0.914 ± 0.010 MyBench.int1e7UJavaSort sample 200 1.144 ± 0.009 s/op 1.120 ± 0.010
所以,我的这个没有特殊优化的算法程序在这些数据集上要比Java自带算法快大概 10-15% 。
在1000.000数据级,包含 10% 或者 1% 的随机重复数据的均匀增加数据集上,我的算法表现的也不差。
Benchmark Mode Cnt Score Error Units Corrected ._1e6Iwf010 sample 20705 9.701 ± 0.033 ms/op ._1e6Iwf001 sample 148693 1.344 ± 0.003 ms/op 生成正确的基准数组 .int1e6Iw010BleedSort sample 4159 49.377 ± 0.571 ms/op 39.68 ± 0.60 .int1e6Iw010JavaSort sample 3937 52.139 ± 0.229 ms/op 42.44 ± 0.25 .int1e6Iw010QuickSort sample 3899 52.457 ± 0.210 ms/op 42.76 ± 0.23 10% 重复数据 .int1e6Iw001BleedSort sample 6190 32.821 ± 0.219 ms/op 31.48 ± 0.22 .int1e6Iw001JavaSort sample 8113 24.910 ± 0.079 ms/op 23.57 ± 0.08 .int1e6Iw001QuickSort sample 8653 23.367 ± 0.056 ms/op 22.02 ± 0.06 ^^ 1%
但是,这个算法在只有10.000左右的小二项分布的数据集 (~bin(100,0.5))(译者加:考虑到括号里面是公式代码,并没有修改内部英文括号符号成中文符号)上表现的很差。 在这些数组中,平均下来,出现50这个数字的次数是795.5,而出现40组重复数组的次数是108.4。
同时,在排序1000.0000量级的大数组的时候,这个算法要比 Arrays.sort() 慢两倍左右。这些数组都有很多的重复数据(比如有的大小为1e6的数组里只有450个不同的数值)。
Benchmark Mode Cnt Score Error Units Corrected ._1e4bin100 sample 152004 1.316 ± 0.001 ms/op ^^ for correction .int1e4bin100BleedSort sample 148681 1.345 ± 0.001 ms/op 0.029 ± 0.002 .int1e4bin100JavaSort sample 150864 1.326 ± 0.001 ms/op 0.010 ± 0.002 .int1e4bin100QuickSort sample 146852 1.362 ± 0.001 ms/op 0.046 ± 0.002 .int1e6bin1e4BleedSort sample 75344 2.654 ± 0.005 ms/op - .int1e6bin1e4JavaSort sample 146801 1.361 ± 0.002 ms/op - .int1e6bin1e4QuickSort sample 76467 2.615 ± 0.005 ms/op -
在排序小型的(10.000, 100.000)均匀随机数组下,这个算法表现尚可,但是并不比系统算法更好。
MyBench.int1e4UBleedSort sample 216492 0.924 ± 0.001 ms/op 0.683 ± 0.002 MyBench.int1e4UJavaSort sample 253489 0.789 ± 0.001 ms/op 0.548 ± 0.002 MyBench.int1e4UQuickSort sample 217394 0.920 ± 0.001 ms/op 0.679 ± 0.002 MyBench.int1e5UBleedSort sample 18752 0.011 ± 0.001 s/op 0.009 ± 0.002 MyBench.int1e5UJavaSort sample 22335 0.009 ± 0.001 s/op 0.007 ± 0.002 MyBench.int1e5UQuickSort sample 18748 0.011 ± 0.001 s/op 0.009 ± 0.002
总而言之,在内存不是很紧张的情况下,针对适当的大数据集,我会建议把分布搜索算法做为一个有效的补充选项。
最后,让大家来认识一下二项分布的一些数据集 bin(100, 0.5) 和 bin(1000, 0.5),
这里是两个随机抽样了100个数据的数据集(使用R语言生成)。
> rbinom(100, 100, 0.5) [1] 43 49 51 47 49 59 40 46 46 51 50 49 49 45 50 51 50 49 53 52 45 53 48 56 45 [26] 47 55 47 53 53 56 41 47 42 51 51 46 49 49 52 46 48 49 50 48 56 54 49 53 52 [51] 54 48 45 45 50 48 54 49 52 50 48 48 49 45 54 54 50 41 53 45 51 48 53 52 52 [76] 50 53 47 55 47 60 54 52 56 45 46 54 46 38 43 53 45 62 48 52 52 52 49 52 56 > rbinom(100, 1000, 0.5) [1] 515 481 523 519 524 516 498 473 523 514 483 496 458 506 507 491 514 489 [19] 475 489 485 507 486 523 521 492 502 500 503 501 504 482 518 506 498 525 [37] 498 491 492 479 506 499 505 497 510 479 504 510 485 488 495 519 522 490 [55] 517 511 511 488 519 508 475 521 505 493 480 498 490 492 492 476 490 506 [73] 496 505 521 518 506 509 477 483 509 493 497 501 483 502 470 515 519 509 [91] 510 496 477 508 506 481 490 511 498 476